
Time Savings
Research that previously took analysts days now completes in under seven minutes.
Investment firms are huge consumers of company research. Their analysts need to gather data about companies from multiple sources and regional databases. Search engines have their challenges in serving up releavent results. The information analysts need has to be filtered , collated and summarized before completing the analysis. This typically takes a few days for a single company. Our clients came to us needing a solution that could deliver comprehensive due diligence at scale, in minutes instead of days. We built DeepIntel as a production system architected for high scalability. The system processes thousands of research requests daily, delivering comprehensive reports in under seven minutes with enterprise-grade reliability.
Investment analysts spent days manually gathering, filtering, and analyzing information about companies before making investment decisions. They needed to research compliance issues, fraud indicators, tax defaults, lawsuits, and whistleblower reports across multiple countries and regions. The manual process was slow, incomplete, and couldn't scale with the volume of companies requiring due diligence.
Traditional search engines returned unreliable results, mixing relevant findings with noise. Critical information was scattered across specialized databases like Panama Papers, Offshore Leaks, and Violation Tracker sites. Country-specific sources and regional variations made comprehensive research even more challenging.


We built a sophisticated agentic AI system that automates the entire research workflow—from initial search through final report generation. The system handles customizable search terms including company name, location, and risk indicators like non-compliance, fraud, tax default, lawsuits, and whistleblower reports.
Intelligent agents simultaneously search internal databases, external search engines, and specialized sources including Panama Papers, Offshore Leaks, and Violation Tracker sites. The system adapts queries based on country and region, using appropriate local sources and search terms.
Retrieved links are automatically deduplicated to eliminate redundant processing and ensure efficient resource usage.
Web scraping agents extract content from approximately 130 URLs per research query. The system is architected to avoid rate limit restrictions, handle bot detection mechanisms, and implement intelligent retry logic for failed requests.
An LLM evaluates extracted data for relevance, filtering out the noise that search engines inevitably return. This ensures only pertinent information proceeds to analysis, dramatically improving report quality.
The system processes information that often exceeds one million tokens—beyond the capability of current LLMs. We developed an iterative processing approach that analyzes information sources in manageable chunks, generates intermediate outputs, and then combines these using LLMs to produce comprehensive summaries and detailed reports.
Users receive email notifications and system alerts when reports are ready, typically within seven minutes of request submission.
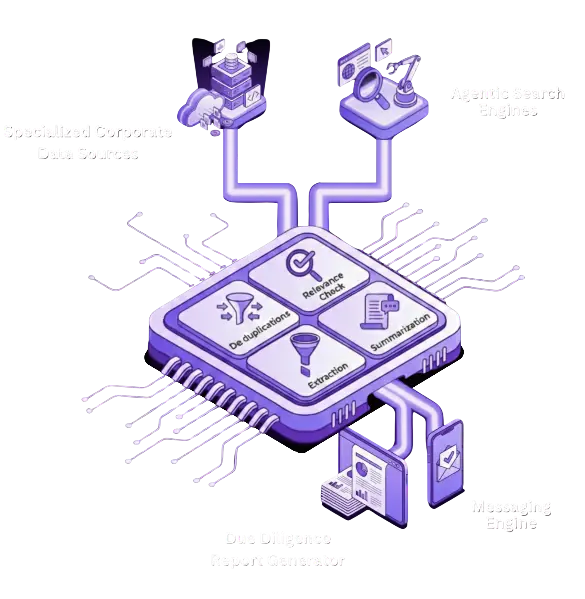
The system is
built on a microservices architecture deployed as a cloud-based service for high
scalability. This enables
processing over 3,000 reports daily—a number growing rapidly as more customers adopt the
service.
Critical performance requirements demanded sophisticated engineering:
Response time under seven minutes even at peak loads
Rate limit management across multiple data sources
Bot detection avoidance for reliable scraping
Robust error handling and retry mechanisms
Scalable architecture supporting thousands of concurrent research requests
The iterative LLM processing approach overcomes context window limitations, enabling analysis of million-token documents by intelligently chunking, processing, and synthesizing information across multiple LLM calls.
Research that previously took analysts days now completes in under seven minutes.
Processing 3,000+ reports daily and increasing volumes significantly month over month.
Comprehensive global research across multiple languages, regions, and specialized databases that analysts couldn't access or monitor manually.
AI-powered relevance filtering ensures reports focus on pertinent information, not search engine noise.
Every company receives the same thorough research across all relevant risk indicators and sources.
Investment firms make faster, better-informed decisions with comprehensive due diligence that would be impractical manually.
Coordinated agents handle search, extraction, filtering, and analysis—each specialized for its task.
LLM-based filtering addresses the fundamental problem of unreliable search results.
Innovative iterative approach enables comprehensive analysis beyond standard LLM limitations.
Country and region-specific search strategies with specialized database access.
Cloud microservices architecture handling thousands of daily reports with consistent sub-seven-minute response times.
Integration with Panama Papers, Offshore Leaks, Violation Tracker, and regional compliance databases.
A list of all the companies searched can be found and viewed at any point of time to check the reports or relevant links related to that category of the company.
Users can bookmark their companies which makes it easier for them to view it if needed in a future point of time.


When a user queries a company name and its location, agents fetch all the external data with respect to the categories which is passed through a relevance agent to keep only the relevant data.
The report consists of various sections of the company like Allegation or Fraud, Whistleblower, Debt, Tax Default, Warnings , Non Compliance and Court cases which involve the company. Users can go to the link and see if they are interested in it.
All the relevant urls are processed by agents and extract the data and a report which includes all categories are generated.
The users also have an option to download the report and view it at any point of time.


The Additional Insights module provides a detailed, category-wise company report with full traceability and source grounding. Each insight is linked to its originating data source, enabling seamless redirection for deeper verification and context.